


Ā
Ā
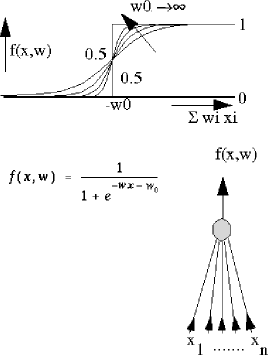
Figure 3:
A single neuron (right) and its input-output relation based on a sigmoid
function (above)
The feed-forward neural networks that are discussed here are configured by single neurons such as shown in figĀ 3 . Their inputs are linearly weighted and summed. The result is mapped by a squashing function on the (0,1) interval. Note that for very small weights this function is almost linear and that for very large weights it almost resembles the step function.
Ā
Ā
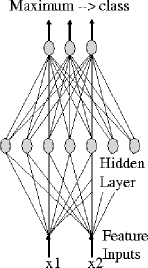
Figure 4:
Feedforward network for 2 features and 3 classes
An entire neural network with a single layer of hidden neurons is shown in figĀ 4 . It has an input for each feature and an output for each class. Classification is done by assigning the label of the class with the highest output to the incoming feature vector. The number of hidden neurons can be freely chosen and determines the maximum nonlinearity that can be reached. Almost any decision surface can be constructed for sufficiently large sets of neurons.
It is important to distinguish the architecture of a neural network from the way it is trained. It has been shown in literature that almost any classifier can be mapped on a neural network. This shows that the architecture is very general and it is thereby not specific. Consequently, from a scientific point of view a neural network implementation of an otherwise trained classifier is thereby not of interest, it does not specifically contribute to a better generalization.
The real interesting point is therefor the way neural networks are trained. If this makes use of the specific architecture, we will call it a neural network classifier. If the training is done otherwise it belongs to the large class of non-neural classifiers and such methods are not considered in this section. Specific neural network training procedures train the network as a whole and iteratively minimize some error criterion based on the network outputs and their targets (derived from the class labels).
Traditionally the MSE criterion is minimized using a gradient descent technique resulting in the well-known error backpropagation training rule. This rule is very slow and only feasible by the heavily improved computer speed in the last decade. Methods that use the second derivative in one way or another (conjugated gradient, Levenberg-Marquardt) can be much faster but might also yield instable results.
A number of observations can be made on the properties of neural network classifiers. They are given here without much argumentation:
Ā
Ā
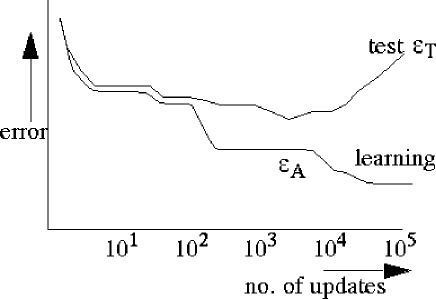
Figure 5:
A neural networks classifier shows increasingly more overtraining for
more updates due to an increasing effective classifier complexity
Adrian F Clark