


Next: References Up: Uncalibrated Stereo Correspondence Previous: Comparison with a recent
Next:
References
Up:
Uncalibrated Stereo Correspondence
Previous:
Comparison with a recent
This paper has proposed a new effective method for performing features-based stereo correspondence. We have seen that its quality lies not in its accuracy but in a tremendous performance/complexity ratio that makes it particularly suitable as bootstrap for other more accurate methods.
Although the additional cost of the algorithm is only that of computing
the SVD of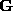
 , the computation time should not be overlooked. The SVD is one of the
stablest numerical matrix operations and its basic complexity is
, the computation time should not be overlooked. The SVD is one of the
stablest numerical matrix operations and its basic complexity is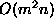 . This is not too bad for a stereo matching algorithm but for large
number of features can become impractical. In numbers, by the SVD
routine provided by the MATLAB package (on a HP9000/730) workstation it
takes about 6s for
. This is not too bad for a stereo matching algorithm but for large
number of features can become impractical. In numbers, by the SVD
routine provided by the MATLAB package (on a HP9000/730) workstation it
takes about 6s for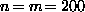 but just 0.2s for
but just 0.2s for . A straightforward remedy would be to zero out very small
. A straightforward remedy would be to zero out very small that have no chances of becoming 1:1 pairings in order to make the
matrix
sparse and allow for optimized numerical solutions. Intriguingly, due to
its extreme neatness and regularity, the algorithm could lends itself to
real-time hardware implementations, thanks to some general purpose,
scalable SVD hardware engines such as those proposed for trajectory
control of robots [
13
]. Other more complex algorithms can hope for real-time performance only
by implementations on expensive parallel architectures.
that have no chances of becoming 1:1 pairings in order to make the
matrix
sparse and allow for optimized numerical solutions. Intriguingly, due to
its extreme neatness and regularity, the algorithm could lends itself to
real-time hardware implementations, thanks to some general purpose,
scalable SVD hardware engines such as those proposed for trajectory
control of robots [
13
]. Other more complex algorithms can hope for real-time performance only
by implementations on expensive parallel architectures.
Ā
Ā
Ā
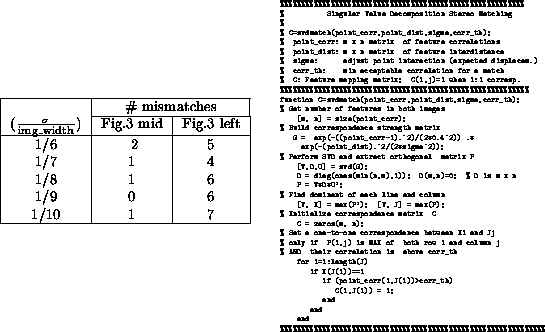
Figure 4:
LEFT: Sensitivity of results to variations of . RIGHT: MATLAB code of the SVD stereo correspondence method proposed in
this paper.
. RIGHT: MATLAB code of the SVD stereo correspondence method proposed in
this paper.
Another interesting property of this algorithm is that it does not explicitly require a specific correlation threshold for a feature pair to be accepted as what matters is its relationship with others competing matches. In all the examples shown in the previous section the correlation threshold was set to as low as 0.4, whereas normally it is set to 0.7/0.8 (see e.g. [ 14 ]).
However, the black-box nature of the algorithm is a limitation. For instance, it is not possible to embed any non-pairwise constraint, such as the disparity gradient or the geometric ordering constraint[ 6 ] . Some of these problems could be bypassed, though. If, for instance, in a two-stage approach a few definitely good matches are known beforehand, one could recover a very coarse epipolar geometry and embed the deviation from epipolar lines in the correspondence strength function in Equation ( 2 ) and then apply the algorithm to all the other features.
Although some standard pruning method could be easily applied to cut down rogue matches, other pair-wise similarity measures could be more interestingly tried out in place of (or in conjunction with) correlation in Equation ( 2 ). In particular, multi-band correlation and measures of neighboring matches support - such as the strength of the match used in [ 14 ] - seem the most promising ones.
Lines are more stable features than corners and recently a tensor-based method has been found for uniformly use line and points to estimate the epipolar geometry (e.g., see [ 11 ]). A natural extension of the algorithm that should be easy to implement, is to apply it to properly parameterized lines.
Finally, since it is possible that the algorithm will be used by other researchers due to its simple implementation and reasonably good performance, the commented MATLAB code is given in Figure 4 .
Thanks to Stephen Pollard for useful suggestions.
Maurizio Pilu