


Pairwise geometric histograms (PGH) are a representation used for the recognition of rigid shape. They have been shown to be a robust solution for the recognition of arbitrary 2D shape in the presence of occlusion and scene clutter [1], [2], [5] and [6]. The method is both statistically founded and complete in the sense that a shape may be reconstructed from its PGH representation ([7]). The complete algorithm comprises a number of stages:
Ā
Ā

Figure 1:
PGH entry for a Single Line Comparison
The optimisation of the representation process can be viewed as a way of matching the stored model data to the difficulty of the recognition task. Thus we can expect to have to construct measures which quantify: repeatability, discriminability and compactness. As each of these cannot be measured using a single unified statistic we can expect to have to use optimisation procedures which operate on non-comensurate objectives. We will now define the motivation and construction of our measures.
Prior to constructing geometric histograms it is necessary to decide on
the histogram scale to be used. The choice of maximum perpendicular
distance , is driven by two conflicting requirements. On one hand
should be small enough that the PGH represents
local
shape and is robust to missing data and occlusion. On the other hand
should be large enough so that shape information in each PGH is
distinct. Prior to the present work, rule-of-thumb used was to ensure
that most of a shape was encoded into each histogram.
, is driven by two conflicting requirements. On one hand
should be small enough that the PGH represents
local
shape and is robust to missing data and occlusion. On the other hand
should be large enough so that shape information in each PGH is
distinct. Prior to the present work, rule-of-thumb used was to ensure
that most of a shape was encoded into each histogram.
The simplest type of histogram is constructed by restricting angles to
the range 0 to and distances to 0 to
. This histogram is invariant to reflections of the shape data about the
reference line and is described as
mirror symmetric
. Mirror reflection invariance is not always desirable and can be
removed by using the direction of angles (clockwise or anti-clockwise)
to extend the range of angle measurements to
and distances to 0 to
. This histogram is invariant to reflections of the shape data about the
reference line and is described as
mirror symmetric
. Mirror reflection invariance is not always desirable and can be
removed by using the direction of angles (clockwise or anti-clockwise)
to extend the range of angle measurements to to
. This doubles the number of entries in a histogram and thus the
computation needed for histogram matching, but also increases the
sparseness so improving robustness of matching in cluttered scenes.
Depending on whether the point of intersection between the two line
fragments (FigureĀ
1
) lies to the right or left of the reference line
can be signed, thus again doubling the area of the histogram and
extending the distance range to
to
. This doubles the number of entries in a histogram and thus the
computation needed for histogram matching, but also increases the
sparseness so improving robustness of matching in cluttered scenes.
Depending on whether the point of intersection between the two line
fragments (FigureĀ
1
) lies to the right or left of the reference line
can be signed, thus again doubling the area of the histogram and
extending the distance range to to
.
to
.
Typically, there are three
types
of PGHs used (FigureĀ
2(a)
): and
and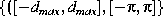 , known as `mirrored', `rotated' and `directed' histograms respectively,
which encode different degrees of geometric invariance
, known as `mirrored', `rotated' and `directed' histograms respectively,
which encode different degrees of geometric invariance
 . In order to add robustness to the PGHs a local circular window is
applied centred around the mid-point of the reference line (FigureĀ
1
). The associated histogram is constructed by making entries for each
line truncated to the circular window. The radius of this window is a
continuous variable and equal to the maximum perpendicular distance (
) value of the associated histogram. The
parameter is normally set in accordance with the object size so that the
maximum amount of useful data is constructed during matching. Its
determination is a trade-off between the local scale of the object and
the amount of clutter in the window. Associated with this parameter is
the width of the bins on the perpendicular distance axis of the PGHs.
The width parameter can be determined from the accuracy of the polygonal
segmentation process. In this work we will simultaneously optimise the
value of
and the histogram
type
but the bin width remains at its theoretical value [7].
. In order to add robustness to the PGHs a local circular window is
applied centred around the mid-point of the reference line (FigureĀ
1
). The associated histogram is constructed by making entries for each
line truncated to the circular window. The radius of this window is a
continuous variable and equal to the maximum perpendicular distance (
) value of the associated histogram. The
parameter is normally set in accordance with the object size so that the
maximum amount of useful data is constructed during matching. Its
determination is a trade-off between the local scale of the object and
the amount of clutter in the window. Associated with this parameter is
the width of the bins on the perpendicular distance axis of the PGHs.
The width parameter can be determined from the accuracy of the polygonal
segmentation process. In this work we will simultaneously optimise the
value of
and the histogram
type
but the bin width remains at its theoretical value [7].
PGHs have been shown to be applicable to extremely large databases for hundreds of thousands of objects [6]. These results are based on an extrapolation of storage capacity from a much smaller test set. In order to construct a large recognition system automatically we will require an automated procedure for selecting the parametric representation of a line in terms of the free parameters specifying a PGH - the very nature of this problem requires us to take multiple competing objectives into account.
Frank Aherne