


The experiments summarised below were all performed on images from the
M2VTS multi-modal database [
14
]. This publicly available database contains facial images and
recordings of speech from 37 persons. For each person, 5 `shots'
 acquired over a period of several weeks are available. A single shot is
made up of 3 sequences: (1) a frontal-view sequence in which the person
is counting from 0 to 9, (2) a rotation sequence in which the person is
moving his or her head and (3) a rotation sequence identical to the
previous one except that, if glasses are present, they are removed. Some
sample images from the M2VTS database are shown in Figure
2
.
acquired over a period of several weeks are available. A single shot is
made up of 3 sequences: (1) a frontal-view sequence in which the person
is counting from 0 to 9, (2) a rotation sequence in which the person is
moving his or her head and (3) a rotation sequence identical to the
previous one except that, if glasses are present, they are removed. Some
sample images from the M2VTS database are shown in Figure
2
.

Figure 2:
Sample images from the M2VTS database illustrating changes in the
appearance of a client.
To demonstrate the overall recognition performance of the optimised
robust correlation method an experiment was performed using frontal-view
images from one of the two rotation sequences of the first four shots.
Several different search methods were implemented and evaluated: the
technique based on random perturbations described in Section
2.2
, the Simplex algorithm due to Nelder and Mead [
15
], a direction set method due to Powell [
15
] and simulated annealing combined with Simplex [
15
]
. Only two of these fulfill the near real-time requirements, the random
perturbations and the Simplex, and the results obtained using these are
presented here. The recognition performance was estimated using the
leave-one-out
methodology in which training and testing sets are disjoint. The
receiver operating characteristics (ROC) are shown in Figure
3
a. The equal error rates (EERs) for the random perturbations and the
Simplex are 5.4% and 9.6%, respectively.
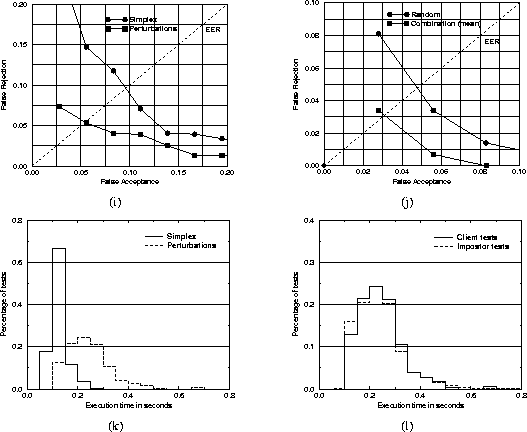
Figure 3:
Performance of the optimised robust correlation: recognition performance
as a function of (a) search method and (b) number of test images used;
execution times on SGI Power Challenge for (c) two different search
methods (client tests only) and for (d) client and impostor tests using
random perturbations for optimisation.
An example of a client test output is shown in Figure 4 . The combined image in Figure 4 c was obtained by transforming the reference image and then selecting rows interchangeably from the transformed image and the test image. The response image in Figure 4 d was computed by applying the robust kernel to each pixel in the overlapping region between the transformed reference image and the test image. Mismatches appear in areas with hair change and non-rigid deformations (ie. the mouth region) as well as in the parts of the face not visible in both frames. Due to the robust kernel these mismatches do not have a disproportionate influence on the match score and the client test is successful.

Figure 4:
An example of a client test: Person JR shot 1 against shot 3.
The sampling density used for computing the ROC curves shown in Figure 3 a was established experimentally. Using the same dataset as in the above experiment, the sampling density was increased from 0.5% until no further improvement of performance was achieved. This point was reached at a sampling rate of 4%. The ROC curves for different sampling densities are shown in Figure 5 a. The difference in EER between the two extreme cases (0.5% and 4%) is 4.3%. To experimentally confirm the convergence properties of the optimised robust correlation the relative estimation error with respect to a full correlation was computed for a subset of client and impostor tests and for different sampling densities (see Figure 5 b). The median relative error at a sampling rate of 4% was 1.5% and 1.4% for the client and impostor tests, respectively.
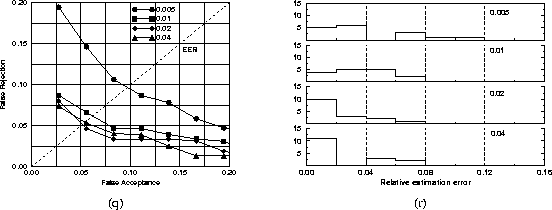
Figure 5:
The impact of sampling density on (a) recognition performance and (b)
relative estimation error.
To illustrate the benefits of applying the method to image sequences an experiment was performed using several test images per shot. Since a single image-to-image comparison is completed in near real time (see Figures 3 c and 3 d), it is possible to repeatedly apply the method to a continuous stream of test images. For standard video equipment the method allows every fourth or fifth frame to be matched. By combining the scores obtained on the sequence, this approach will on average outperform the one in which a single, randomly-chosen test image is used.
For this experiment the images were selected from the frontal-view sequences of the first four shots in the M2VTS database. A lip tracker described in [ 16 ] was used to select `shut-mouth' images. The ROC curves obtained when using sequences of test images and single, randomly-chosen ones are shown in Figure 3 b. The EERs for the two cases are 3.1% and 4.8%, respectively. Note that this approach effectively includes normalisation for 3D rotation (assuming that the state of the reference image with respect to rotation will always be present in the test sequence) and changes in facial expression. Thus, the method may be used for selection of the best image for frontal-face recognition, eg. as a front-end to a more reliable, but slower, method.
The execution time for the optimised robust correlation depends on the sampling density and the number of optimisation steps (which is a function of the similarity of the compared images and the starting point in the multi-dimensional search space). The histogram of execution times shown in Figure 3 d was obtained from more than 16000 randomly selected imposter and client tests. On average, a single identification test took 0.24 seconds. The trade-off between recognition performance and execution time is apparent when comparing Figures 3 a and 3 c.
Kenneth Jonsson