


The two methods both require an initial pre-processing stage which separates the objects from the original images of the slides. This process can be relatively simple since the idea is that the robustness of the identification is built into the subsequent stages. Only approximate centering of each object within the cropped sub-images is required. The basic ideas behind the two chosen methods are now given.
This approach is model based and therefore requires an application specific model to be produced which for this particular application is based on the observation that many types of pollen have a thick boundary, or double-edge when viewed through an optical microscope. A snake is then used to detect this double-edge if it is present. The amount of this type of edge that is detected is used to discriminate between pollen and non-pollen. Snakes are used because they will fill in the gaps in the pollen grains border which are caused by physical variations whilst still demanding that the border is continuous.
Snakes are controlled continuity splines whose shape is controlled by its internal forces, its external constraints and the image forces. The internal forces are a generic part of the snake model and can be altered to make the snake act like a thin plate spline or like a membrane, for this work the snake is made to act like a thin plate spline since the boundary of the pollen grains should be smooth, with no first or second order discontinuities. The external constraints can be used to force a part of the snake to attach itself to a particular point, in this work there are no external constraints. The image forces determine which parts of the image a snake is ``attracted to'', in this work the forces are calculated so that the snake is pulled towards any double edges in the image.
The image forces need to attract the snake towards double edges in the
image, so the first step is to detect these. The detection of the double
edge can be simplified by using the general circular nature of the
majority of pollen. A simple transform from cartesian space to -space results in the edge of the pollen being approximately a straight
line in the
-space results in the edge of the pollen being approximately a straight
line in the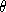 dimension. Having performed this transform a Gabor edge detector is used
which is tuned to the edge width and orientated in the
direction.
dimension. Having performed this transform a Gabor edge detector is used
which is tuned to the edge width and orientated in the
direction.
Once the oriented edge detector has been applied the double edge itself
can be located. This is done by applying a simple filter, given by,
given by,

The filter detects a double line where the lines are separated by
g
pixels and are
l
pixels long. The use of an extended filter reduces the noise from
isolated pairs of pixels. In order to allow for changes in width of the
double edge, and to take account of the fact that the edges are not
perfectly straight, the edge detected image is blurred before being
filtered. In our experiment
g
was 6 pixels, this was determined by observing the width of the double
edge in the sample pollen grains,
l
was chosen heuristically to be 10 pixels. Figure
1
shows the result of transforming a pollen and a non-pollen object into
-space and performing the double edge detection.
The output of the filter is now negated and treated as an energy landscape. The image forces are calculated from the slope of the landscape so as to pull the snake into the energy minima i.e. to the points on the original image which have a double edge.
Ā
Ā

Figure 1:
Objects in
-space (top) and after performing double edge detection (bottom). Left:
Pollen (76% edge detected), Right: Non-pollen (33% edge detected)
The Paradise neural network was originally designed for the recognition of static hand gestures [ 9 ] but later work demonstrated its more general ability to classify general objects [ 10 ][ 11 ]. The Feature Recognition Network (FRN) developed by Hussain and Kabuka [ 12 ] provided the inspiration for this network, giving deformation tolerance whilst keeping the network small and practical. Unlike the FRN, however, the Paradise network is able to work with grey-scale images and can be trained on or off line.
It uses a method based on creating small templates (Pattern Detection Modules) which are responsible for identifying the important features of an object. The identification is then made on the basis of linking several of these templates together in a classification layer. The network has a 3 layer architecture:
The FE layer consists of a single layer of FE planes. Each plane extracts a certain type of feature from the input image. For pollen detection 4 FE planes were used to extract horizontal and vertical lines at two frequencies. These frequencies were chosen by examining the lines extracted from pollen images at a number of frequencies and choosing those which generated the most information.
This layer builds up a set of templates from the features produced in the FE layer. Due to the relatively small size of these templates, they can often be reused to represent parts of many objects. The templates are generated automatically during training and the network architecture makes them robust to small translations and deformations.
Having created the templates the object is represented using a number of the templates, this information being encoded using links to a classification cell in the classification layer. Thus, each class of objects is represented by a classification cell. When subsequent objects are presented to the network the existing classes are examined to see if a sufficiently good representation already exists, if not a new class is created.
There are a number of parameters which can be set to control the type of recognition which is performed by the network. The majority can be set using heuristics and generally stay fixed for a given application. Once these are set the ``classification threshold'' parameter is used to determine the degree of match that is required between the input object and the internal template model. Whilst the classification threshold greatly affects the response of the network Banarse [ 10 ] has shown that in terms of the qualitative results it is only important to get the value in the ``right area'', i.e. the changes in network behaviour are gradual with changing threshold. For all of the results reported the classification threshold was chosen to be 0.26, which is a fairly loose threshold, reflecting the variability of the images of pollen.
The Paradise network automatically generates it's classes when an unfamiliar object is presented to it. In order to make a ``real world'' classification the network must be told which ``real'' or meta-classes to associate with the Paradise classes in a supervised learning session. This training can be performed at presentation time or after the network has been trained on a large number of images. The second approach is preferable as an operator can view all of the objects associated with a class and make a swift judgement as to the nature of the class. With the first method the operator must identify each object individually, a time consuming task. This approach however would allow the network to perform an analysis of the relationship between the Paradise classes and the ``real world'' classes and is useful for testing purposes. Any classes containing mixes of real world classes could be subjected to further examination using a second Paradise network with greater discriminating power.
Mr I France