


Face recognition in general and the recognition of moving people in natural scenes in particular, require a set of visual tasks to be performed robustly. These include (1) Acquisition : the detection and tracking of face-like image patches in a dynamic scene, (2) Normalisation : the segmentation, alignment and normalisation of the face images, and (3) Recognition : the representation and modelling of face images as identities, and the association of novel face images with known models. These tasks seem to be sequential and have traditionally often been treated as such. However, it is both computationally and psychophysically more appropriate to consider them as a set of co-operative visual modules with closed-loop feedbacks. In order to realise such a system, an integrated approach has been adopted which will perform acquisition, normalisation and recognition in a coherent way. FigureĀ 1 illustrates the system design. Images of a dynamic scene are processed in real-time to acquire normalised and aligned face sequences. Typical examples can be seen in FigureĀ 2 . In essence, this process is a closed-loop module that includes the computation and fusion of three different visual cues: motion, colour and face appearance models. Face tracking based upon motion and a face appearance model has been addressed in greater detail elsewhere [ 8 ]. The use of colour is described here. The remainder of this paper then focuses upon person identification within such a framework. Complementary to recognition, appearance-based mechanisms for real-time face pose estimation have been developed which can be used to improve the robustness of detection and alignment [ 7 ].
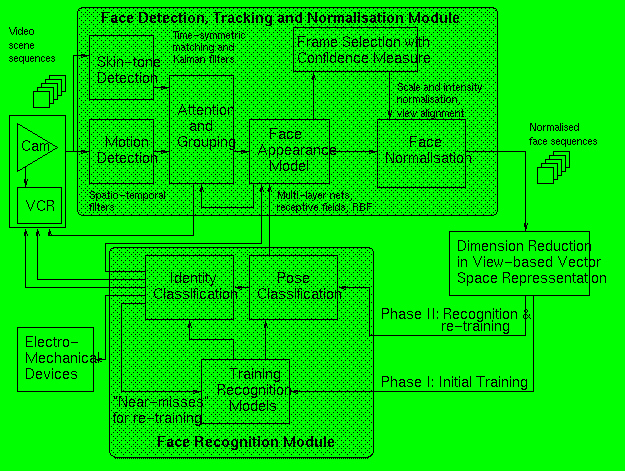
Figure 1:
A framework for face recognition in dynamic scenes.
Much research effort has been concentrated on face recognition tasks in which only a single image or at most a few images of each person are available. A major concern has been scalability to large databases containing thousands of people. However, large intra-subject variability casts doubt upon the possibility of scaling face recognition, at least in this form, to very large populations. A form of biometric ``facial'' recognition using the iris is better suited to such populations. In contrast, the face recognition tasks considered in this paper are characterised by the availability of many images of relatively small groups of individuals. Such data arise from the type of integrated approach to face recognition in dynamic scenes illustrated in FigureĀ 1 . Since these tasks involve recognition of fewer people with more images, they might appear initially to be simpler. However, applications of the ``many people with few images'' variety typically use images captured in highly constrained conditions. In contrast, the tasks considered here require recognition to be performed using sequences acquired and normalised automatically in poorly constrained dynamic scenes. These are characterised by low resolution, large scale changes, variable illumination and occasionally inaccurate cropping and alignment. Recognition based upon isolated images of this kind is highly inconsistent and unreliable. However, the poor quality of the data can be compensated by accumulating recognition scores over time. Many images of a person can be acquired in a few seconds. Given sufficient data, it becomes possible to model class-conditional structure, i.e. to estimate probability densities for each person.
In section 2, the use of Gaussian mixture colour models for face detection and tracking is described. In section 3, four face recognition tasks are defined and possible approaches to each of these are discussed. It is argued that estimating class-conditional densities in a ``face space'' provides photometric models of identity suited to all four tasks. Gaussian mixtures are then presented and evaluated for this purpose. Conclusions are drawn in section 6.
Shaogang Gong