


A system has been developed which uses RBF nodes to obtain, from a database, images which contain regions similar to one chosen by the user as a key. The locations in feature space of these nodes is dictated by the initial region selection and on subsequent classification of the regions within the search-result images. The database contains real home photographs (see acknowledgements) which have not been taken under special conditions and do not contain specially selected subjects. The database used to assess this system contains over 2000 such images each segmented to between 50 and 350 meaningful regions using an automatic segmentation algorithmĀ[ 6 ]. In order to carry out the tests detailed in this paper a subset of 100 images had their most significant regions (usually the 30 largest) manually tagged in order to provide a ground truth with which to evaluate the performance of the system. This information was not used in any way during the query process.
The approach is spilt into two sections: a pre-processing and query a phase. The pre-processing is a one-off task carried out before an query takes place. This carries out an automatic segmentation on the raw image to produce a region map. Feature extraction is then carried out, producing a feature vector for each region.
Once the region map and feature set is built, the query phase can be entered. Here the user identifies key regions by pointing to and clicking on the area of a selected image with the mouse, using a specially designed front end. The feature vector for this region is used to find other images from the database containing regions which have feature vectors closest to it. The ten best matches are shown to the user who is asked to classify each one as ``Yes'' or ``No'' signifying whether it satisfies the query. This information then becomes the training set for the construction of a collection of RBF nodes which are used in subsequent query passes.
Before the system can be used for enquiries, the database must be built. This will contain the raw images, a region map for each image which maps each pixel to a region number, and, for each region, a feature vector giving information about content. The first task in this process is to build a region map which will identify the region which a given pixel belongs to. This is achieved by applying a colour fuzzy C-means (FCM) segmentation using the technique described by LimĀ[ 6 ]. Initially, a coarse segmentation is performed using thresholding to reduce computational requirements. Any subsequently unclassified pixels are then classed using the FCM process. A flood fill algorithm is used to assign a unique identification number to each region. This usually results in a number of extremely small regions which would be of no use to an image retrieval system. To avoid this situation, regions below a certain size threshold are merged and the image is passed to the flood fill algorithm once more. Any regions still below the size-threshold are then assigned to the `zero-region' which contains otherwise unclassified regions and is excluded from any classifier training or query cycles.
A feature vector is then generated for each region in the image. A pixel count is used as the first feature as well as to normalise the remaining features. The colour components are represented by the colour difference system (intensity, red - green, yellow - blue where each colour component is taken as a mean over the region). The regions two-dimensional centroid is given as the mean of all pixel locations. Once the feature vectors for all regions of all images have been calculated, they are normalised to a mean of 0.5 and a standard deviation providing a 95% confidence of each point lying between 0.0 and 1.0 ensuring that there is no bias towards those features with a larger range. Although the current feature set is limited, work is in progress on including texture and shape. The initial aim of this project was to prove the concept of such an approach to database retrieval and so only a limited feature set was used. Now that the concept has been proven, attention will turn to the use of more complex features.
Once the off-line pre-processing is complete, a front-end allows the user to perform on-line queries based on the information obtained here.
A front-end has been specially designed to allow the user to select
regions as query keys and to review and classify the results of the
subsequent searches. It has been written in Java to allow remote access
of a database via the World-Wide Web. To initiate a search, any image
from the test set can be chosen. The interface provides a simple
``point-and-click'' facility for key-region selection enabling the user
to highlight objects of interest in the image. Initially, it is assumed
that the system has no knowledge of the classification of the object in
question. Consequently, when the user is satisfied with the selection
and indicates to the system that the query can proceed, the feature
vector of the given region is used to position a single RBF node in
feature space. Ten images are chosen containing regions with feature
vectors which cause the highest node activation. These are given to the
user for consideration. For each feature vector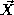 , the RBF node activation
, the RBF node activation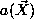 is given as:
is given as:
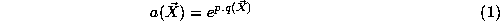
where:

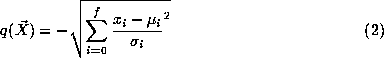
where
f
is the dimensionality of the vector (in this case 6),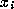 is the coordinate of the feature vector along axisĀi,
is the coordinate of the feature vector along axisĀi,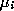 is the coordinate along axisĀ
i
of the RBF node in question, and
is the coordinate along axisĀ
i
of the RBF node in question, and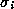 is the standard deviation of axisĀ
i
and
p
is a bias constant. The feature vector for each region in the database
is applied to this formula and ranked according to the output or
``score''. The ten regions which attain the highest score are used as
the result set and presented to the user. Note that only one region per
image is allowed regardless of the activation of other regions.
is the standard deviation of axisĀ
i
and
p
is a bias constant. The feature vector for each region in the database
is applied to this formula and ranked according to the output or
``score''. The ten regions which attain the highest score are used as
the result set and presented to the user. Note that only one region per
image is allowed regardless of the activation of other regions.
The ten images are offered to the user who is invited to provide a response to each one, stating ``Yes'' or ``No'' to each one as to whether it satisfies the query. Upon completion, the responses form the basis of a training set for the construction of a more complex RBF network using a number of nodes based on the clustering of positive and negative training examples. The placement of the nodes is carried out using Kohonen's Learning Vector Quantisation packageĀ[ 5 ], which decides how many nodes are required and places them according to the clustering. The nodes are classified as being positive or negative according to the membership of training examples. All regions in the database are applied to the clusters and are given membership of the cluster which returns the highest vector response. Those regions which display the highest activation of a positive cluster are used for the result set. The ten regions which attain the highest score are offered to the user for consideration and classification. If more than one region per image is identified as being a potential query hit, then only the one considered the closest match is selected. Note that any regions already classified as negative examples by the user are not offered again, regardless of their activation scores although a different region from the same image may be chosen. The user is again invited to classify the results into positive and negative examples, the data from which is added to the training set and passed back to the LVQ algorithm to obtain an updated codebook set. This cycle continues until the user is satisfied with the results.
At any stage, the user can choose another image from the database, not selected by the classification process, in order to `steer' the learning process. For instance, if the user feels that the examples being chosen do not closely match the initial requirements, then they can add further example regions-of-interest to the training data in order to refine the classification ability of the system, simply by displaying the image and clicking on the required region.
Once a set of code-books has been built up which adequately describe a class, then the information is saved for use in later queries. If a selected region is identified as having been previously classified, then the system can immediately revert to using the codebooks previously computed for the region's class. In this manner, a class hierarchy characterising information unique to the user's database and query mannerisms is developed. This encompassing of the user's knowledge into the query process is vital for the success of a system in such an open-ended database. It is envisaged that the final version of this system would be ``pre-programmed'' with a number of generic classes which could be called upon to find objects such as trees, cars, animals and people.
Wood M E J